도커 레이어 & 네트워크
도커 레이어 개괄
- 도커는 현대 컨테이너 기술의 시초석이 되어준 툴
- 리눅스 오픈소스의 다양한 명령어와 노하우가 집약
- 도커는 이를 추상화하여 사용자는 간단한 명령어를 통해 컨테이너를 손쉽게 적용
- 반대로 말하자면 도커의 사용법을 공부하는 것과 기술을 공부하는 것에는 난이도의 격차 존재..
- 다양한 공부 영역
- OCI
- 네임스페이스
- 원리
- 사용법
- 컨트롤 그룹
- 원리
- 유니온 파일시스템
- 레이어 아키텍처
- 네임스페이스
- 스토리지
- 마운트 원리
- 네트워크
- 브릿지
- 통신 구조
- OCI
컨테이너의 핵심 기술
- namespace
- cgroups
- union filesystem
- 디스크 용량을 효율적으로 가져갈 수 있는 방법
- 이미지라는 형태로 활용됨
이미지
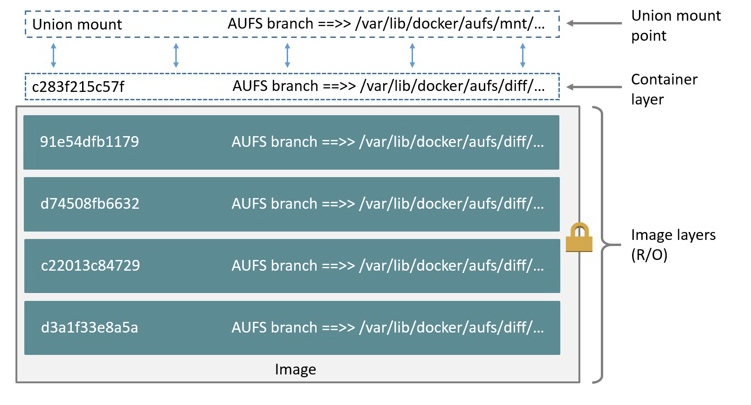
- 컨테이너를 실행하기 위한 파일, 바이너리, 라이브러리와 모든 설정을 포함하는 표준화된 패키지.
- 컨테이너는 이미지에 정의된 파일시스템과 실행할 프로세스를 확인 후 형성됨.
- 프로세스로 컨테이너화되어 실제로 실행되기 이전에 파일 형태로 디스크에 저장된 프로그램
- 작성된 Dockerfile로 빌드되는 무언가!
- 원칙
- 한번 만들어진 이미지는 불변하다.
- 이미지는 레이어를 겹쳐서 만들어진다.
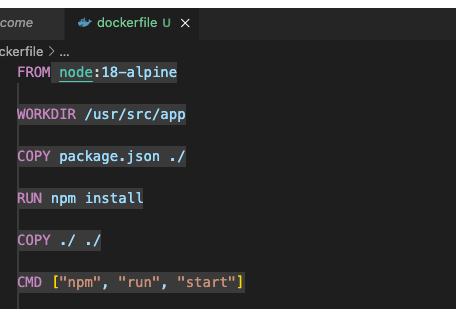
- 각 층은 각각 도커파일에 명시된 한 줄의 명령어의 동작 과정
- 이 모든 구조가 쌓여 이미지로 굳어지고, 컨테이너를 만들 때 thin layer가 한겹 더 쌓임
레이어 구조
- 본격 원리 탐구
- 이미지는 레이어를 쌓아가며 완성
- 이때 각 레이어는 자신의 하위 레이어를 읽기 전용으로 바라보면서 자신의 내용을 새로 덮어쓰기한 새로운 파일 구조 생성
- 이렇게 각 층의 파일시스템을 합쳐서 만드는 것이 union filesystem
Overlay2
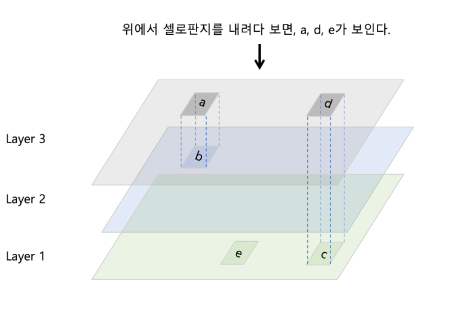
- Overlay는 이를 가능하게 해주는 스토리지 기술
- AUFS, ZFS 등 다양한 스토리지 방식이 존재하나, 가장 많이 쓰임
docker info | grep Storage- RoW
- Redirect on Write
- 스냅샷 기술
- 현재 파일들의 상태를 저장
- 이후 파일들이 변경되어도 다시 스냅샷을 찍어놓은 상태로 복구 가능
- 기본 방식은, 모든 파일들을 복붙..
- 전체 파일을 하나의 스냅샷으로 남겨뒀는데, 한 파일만 수정됐다면 해당 파일의 수정사항만을 디스크에 새로 공간을 할당하여 남기고 한 층으로 간주함
실습
- 이론적인 구조를 봤으니 눈으로 확인하기
- 여기에서부터는 제가 먼저 실습한 내용 정리입니다.
- 조금 더 정리하겠습니다..
전체 디렉토리
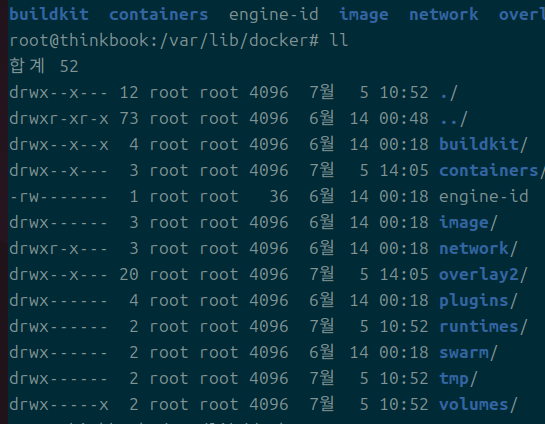
기본적으로 /var/lib/docker에 데이터들이 존재한다.
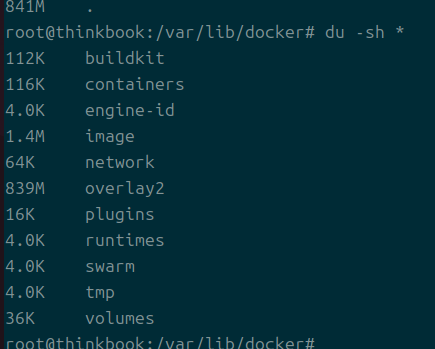
크기를 보면 대충 overlay2가 가장 크다는 것을 알 수 있을 것이다.
buildkit
도커 buildkit 참조.
S-도커 db 확장자 장애를 보면 알 수 있듯 여기에 있는 데이터 잘못 건드리면 난리나니까 조심하도록 한다.
overlay2
실제 스토리지로 활용되는 디렉터리이다.
말 그대로, 도커를 띄우는데 필요한 모든 데이터가 다 들어있다.

이중에서 init이 붙는 녀석은 컨테이너 개수만큼 존재한다.
즉, 컨테이너 생성 시 씌워지는 thin layer라는 것이다.
나머지는.. 뭐 딱 보면 알겠지만 이미지들을 만들 때 쓰이는 레이어들에 대한 디렉토리이다.
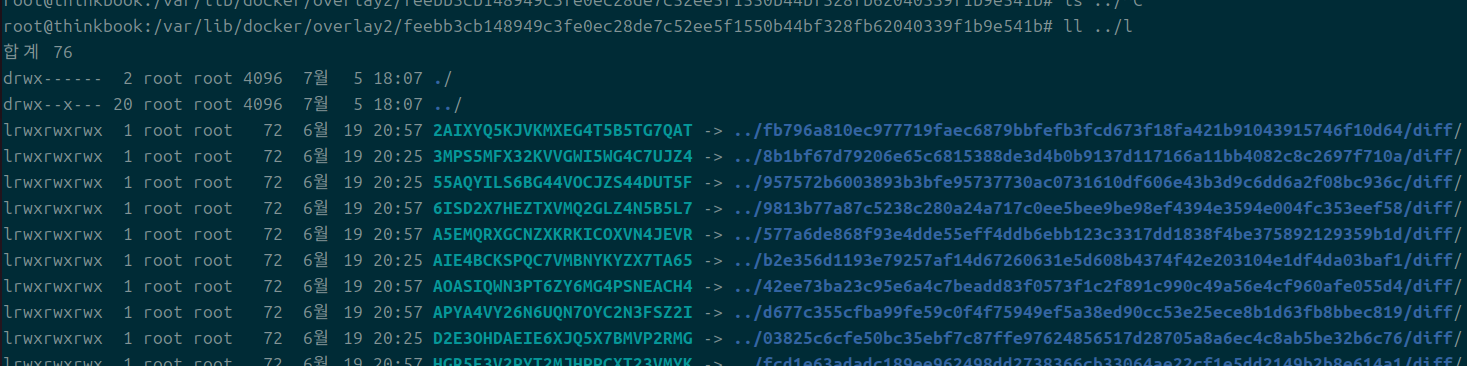
이중에서 l이라는 디렉토리는 심볼릭 링크를 나타낸다.
여기에는 또다른 해시 값들이 각 레이어들의 실제 내용, diff 디렉토리들을 담고 있다.
이 심볼릭 링크가 어떻게 쓰이는지를 보기 이전에 각 레이어 디렉토리를 살펴본다.
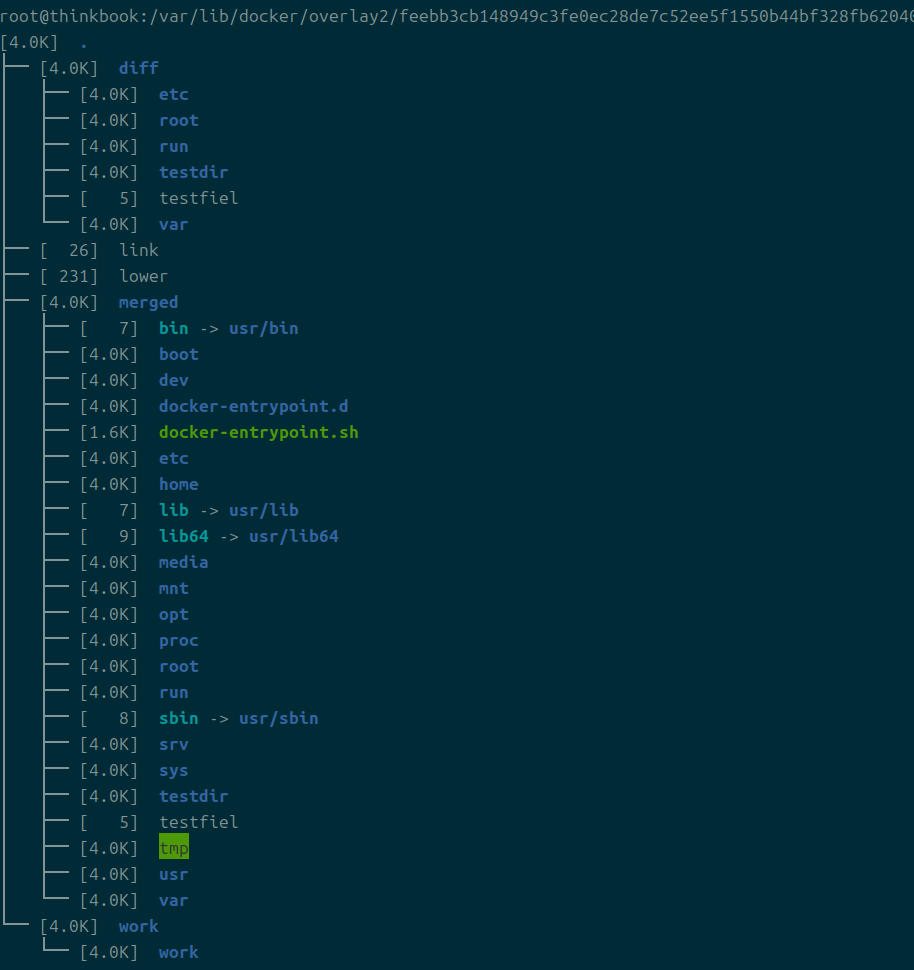
내가 띄워둔 컨테이너의 레이어 디렉터리를 들어가보았다.
init은 컨테이너 생성 직전에 생기는 최종 이미지 디렉터리이고, 실제 컨테이너 디렉터리는 init이 떼어진 디렉터리이다.
각 디렉터리에 대한 설명이다.
- diff
- 컨테이너 생성 이후에 변화하는 부분이다.
- 정확하게는 현재 레이어에서 발생되는 변화를 가리킨다.
- 내가 내부에 들어가 마음대로 testdir, testfile을 만들었었는데 그게 반영된 게 보인다.
- work
- 도커가 컨테이너를 생성할 때 작업용으로 생성하는 디렉터리
- 통합 뷰의 원자성을 위해 생성된다고는 하는데, 잘은 모르겠다
- 실질적으로는 파일을 가지지 않게 된다고 한다.
- merged
- 모든 이미지와 컨테이너 생성 후 생긴 파일을 다 합친 최종 형태
- 컨테이너에 들어가면 접하게 되는 실제 내부와 정확하게 일치한다.
내부 파일의 생김새를 보면 알 수 있듯, 이 녀석들이 실제 컨테이너의 내부를 구성하는 파일들인 것이다.

이 디렉들이 역할은 컨테이너를 inspect해서도 알 수 있다.
이 이미지에서 LowerDir이 엄청 많고, 찾기 어려운 것처럼 보인다.
안 그래도 레이어는 덮어씌워진다 했는데, 왜 그 덮어씌워질 아래 디렉터리가 없는 것이냐!
그것은 lower 파일을 통해서 얻어진다.
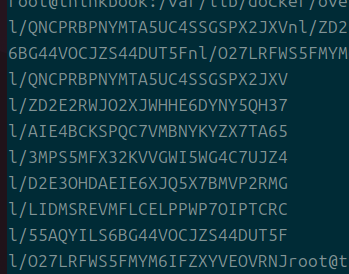
이게 lower 파일인데, 안 속에 l 디렉의 파일들을 가리키고 있다.
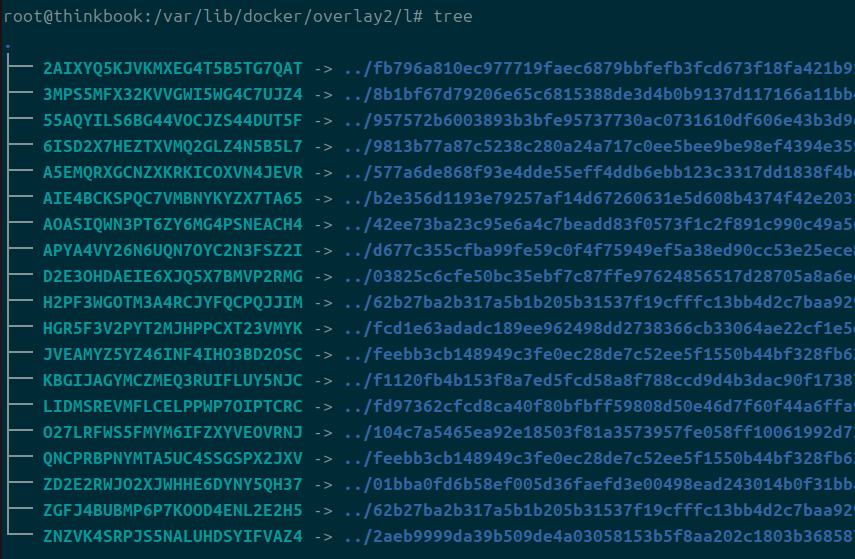
이제야 l 디렉의 내부를 볼 타이밍이 왔다.
그 안에는 또 해시된 어떤 심볼릭 링크가 위치하고 있다.
이 심볼릭 링크는 각 레이어의 결과물인 diff를 가리키고 있다.
정리해보자면, 이렇다.
한 레이어는 자신의 lower 파일에 해당하는 것을 참조할 때 이를 통해서 빠르게 레이어를 쌓고 merged 디렉을 만든다.
스스로를 l디렉에 저장되는 해시값 정보를 link 파일에 남기는 것.
왜 굳이 이렇게 해시값을 만들어 l에 저장할까?
아래는 내 견해이다.
- 읽기 전용 보장
- diff에 담긴 레이어의 상태가 변하지 않았음을 보장하는 좋은 방법 중 하나는 전체를 이용한 해시값을 만드는 것이다.
- 이 경우 누군가 악의적으로 조금이라도 파일을 수정하거나, 오류가 발생하여 이전과 같이 레이어가 쌓이지 않은 순간 해시 값이 바뀌게 된다.
- 중복 레이어 방지
- 각 레이어가 고유한 해시값을 가진다면, 중복을 막아 불필요한 디스크 사용을 방지할 수 있다.
- 빠른 접근
- lower 디렉의 모든 정보를 일일히 파일로 남기는 건 비효율적
- 그래서 마치 파이썬의 dict 타입이나 자바의 HashMap처럼 키값쌍을 두어 빠르게 접근하고자 하는 것이다.
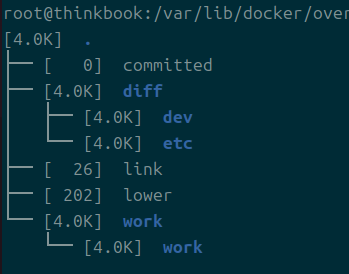
참고로, 컨테이너가 되지 않은 레이어들은 이렇게 생겼다.
각 레이어가 가진 그 자체의 정보는 전부 diff에 있다.
merged가 된 놈이 없는데, 실제 이미지가 될 놈만 merge가 되면 되니까 그런 듯하다.
아무튼 저렇게 작은 dev, etc단위의 변화가 점차 모여서 하나의 큰 컨테이너를 완성하는 것이다.
committed는 commit 기능을 이야기한다.
현재 컨테이너 상태를 commit 한다는 것은 레이어화를 시킨다는 뜻인데, 말그대로 이 레이어가 commit됐다는 것을 말하는 정도의 의미에 불과하다.
달리 말해, 읽기 전용 상태가 됐다를 보장할 수 있는 녀석이기도 하다.
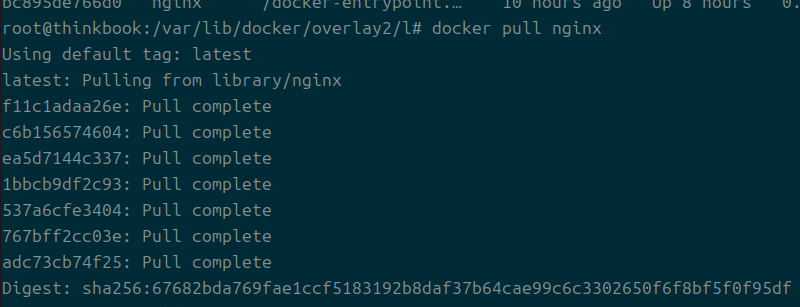
하는 김에 새로 pull을 받아서도 확인해보자

보다시피 새로운 레이어가 들어왔는데, 해당 레이어는 스토리지에 잘 들어왔다.
맨 아래 다이제스트는 태그와 관련된 정보이다.
즉, 위에서 본 image쪽의 repository.json 파일에 담겨있고, 저 다이제스트가 어떤 이미지에 해당하는지에 대한 정보도 담겨있다.
image
직관적인 이름..
이미지들에 대한 정보를 담는다.
하지만 아까 봤듯, 실제 데이터는 전부 overlay2라는 디렉에 저장되고, 이 녀석은 빠르게 이미지 정보를 꺼내기 위해 존재하는 녀석 정도이다.
스토리지는 다양할 수 있기 때문에, 내부에 overlay2라는 디렉이 있다.
만약 내가 스토리지 방식을 aufs로 만드는 설정을 했다면 aufs 디렉이 추가됐을 것이다.
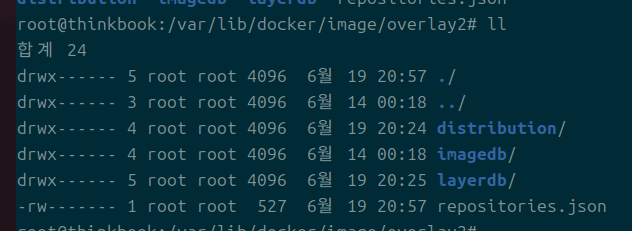
이게 이미지 디렉 안 속의 정보이다.
기본적으로 이미지의 디렉이 있고, 이미지를 구성하는 레이어들의 정보가 있다.
distribution
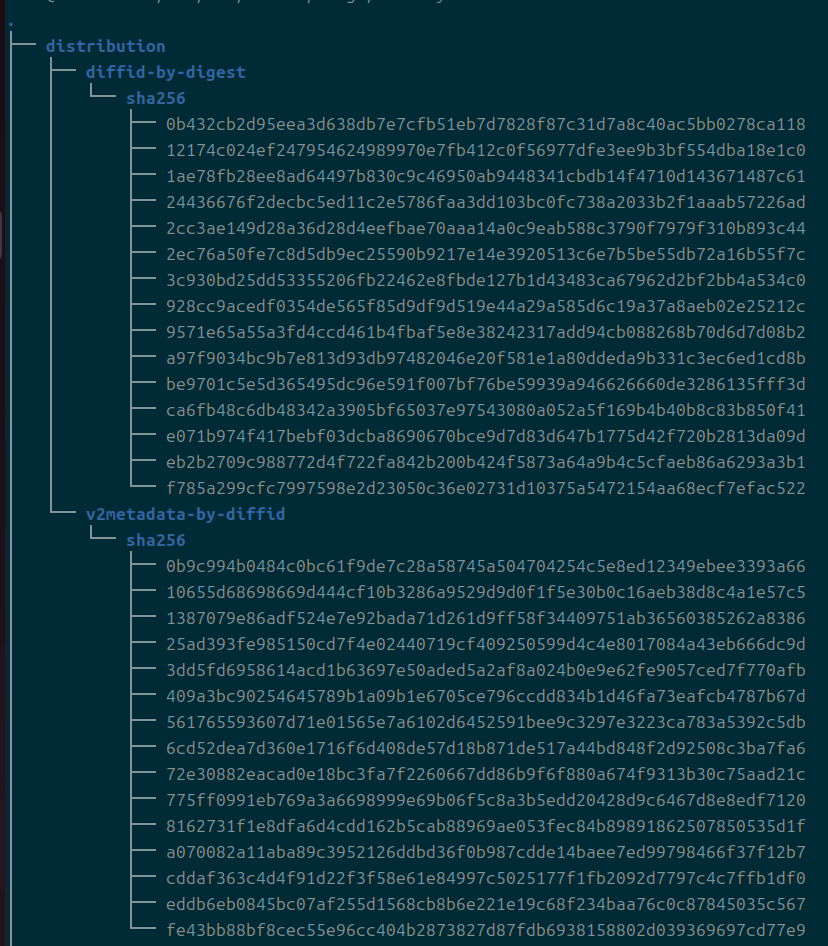
잠깐 distribution이라는 디렉을 먼저 훑자면, 그냥 데이터를 빠르게 조회할 수 있도록 키값 쌍을 저장해두는 디렉이다.
이름은 저렇게 돼있는데, 직접 만져보니까 v2 -> diff -> digest 관계로 키값을 조회할 수 있었다.
근데 왜 by인걸까? to라고 하는 게 맞지 않나..?
그건 이제 도커 개발자들이 알 만한 내용인 것 같다.
repositories.json
원하는 데이터에 더 빠르게 접근할 수 있도록 또 파일이 있다.
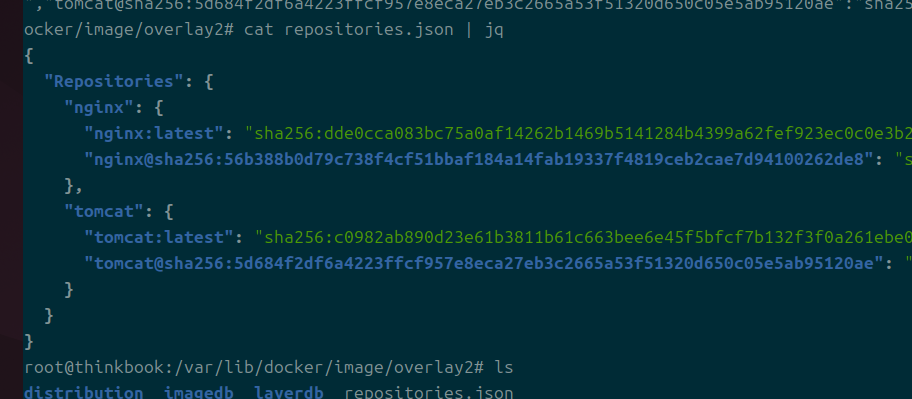
기본적으로 빠르게 이미지를 찾을 수 있도록 json이 형성되어 있다.
태그 정보를 찾을 수 있도록 층위가 한 칸 더 들어간다.
이게 중요한 것이, 사용자가 docker pull 등의 이미지와 관련된 동작을 할 때 Digest라면서 표시되는 해시 값이 여기에 나오는 해시값이다.
한 이미지에 대해서도 다양한 태그와 버전이 존재할 수 있으니, 이러한 접근은 매우 합당하다.
imagdb
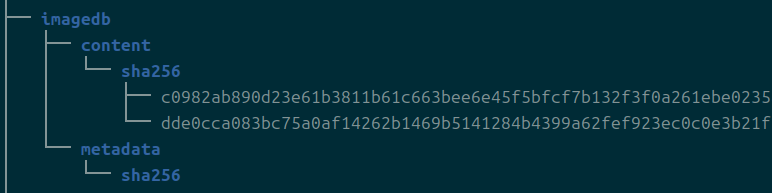
content와 metadata가 나뉘는 이유는 잘 모르겠다.
이것도 개발자한테 물어봐야할 듯.

이미지들의 해시 값이 imaged 안에 있다.
해당 해시 파일들을 까보면 이미지를 inspect하는 것과 비슷한 값이 나온다.
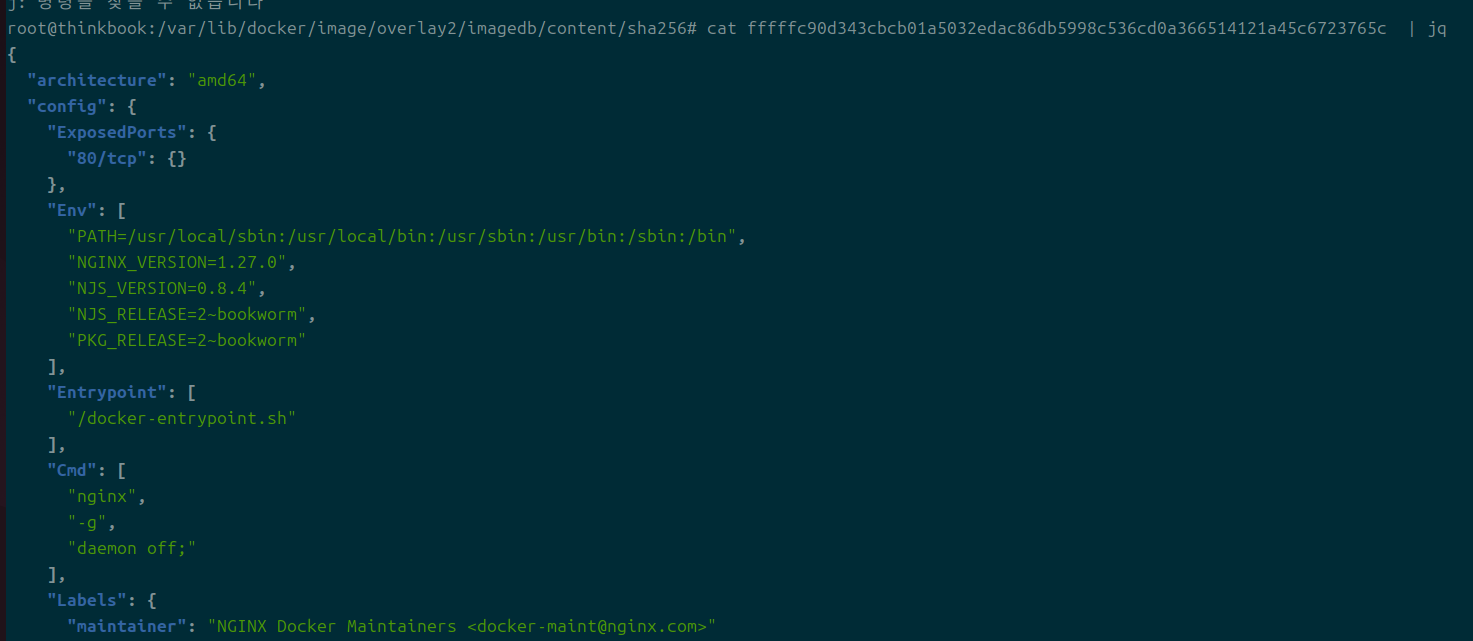
각각은 파일이고, 이러한 정보를 담고 있다.
여기에는 도커파일을 빌드할 당시의 정보도 담겨 있어, 이미지를 직접 만드는 개발자라면 기본적으로 알아두면 좋을 포인트이다.
layerdb
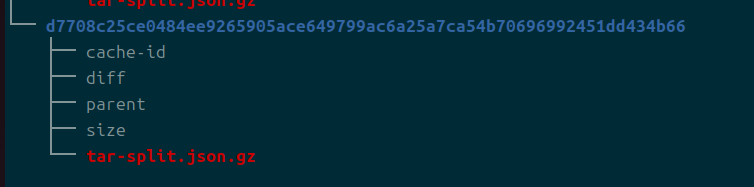

그보다 sha256에 더 깊이 들어가보면 레이어들에 대한 정보가 들어있다.
알아보기는 어렵지만, 각 레이어의 정보를 확실히 담고 있다.
가지고 있는 것이 전부 해시 값인 것을 확인할 수 있다.
- parent
- 부모 레이어 데이터의 해시값
- diff
- 현재 레이어의 변경점들을 담은 데이터의 해시값
- cached-id
- 캐시된 데이터의 해시값
- size
- 크기
이름으로도 알 수 있는 꽤나 직관적인 상황.
- 크기
잠시 정리하자면, images라는 디렉에는 어떤 스토리지를 쓸지에 따라 데이터가 저장된다.
실제 데이터는 해당 스토리지 디렉에 저장될 것이고 여기에는 각 이미지와 레이어의 해시값만 저장되는 장소인 것이다.
빠르게 컨테이너를 실행하고 불러오기 위한 해시테이블이 들어있는 것이다.
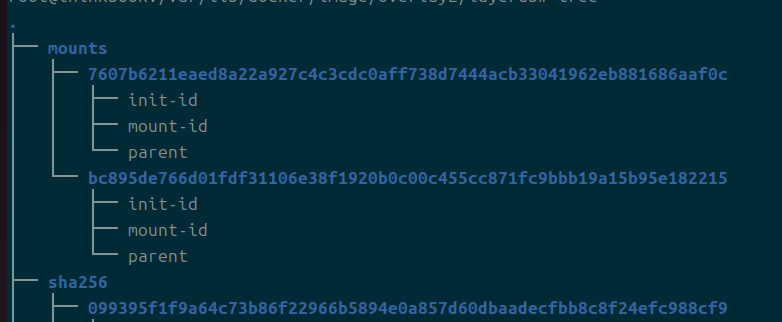

그러한 데이터들은 sha256에, 실제로 컨테이너가 띄워질 때는 mounts 디렉에도 들어가게 된다.
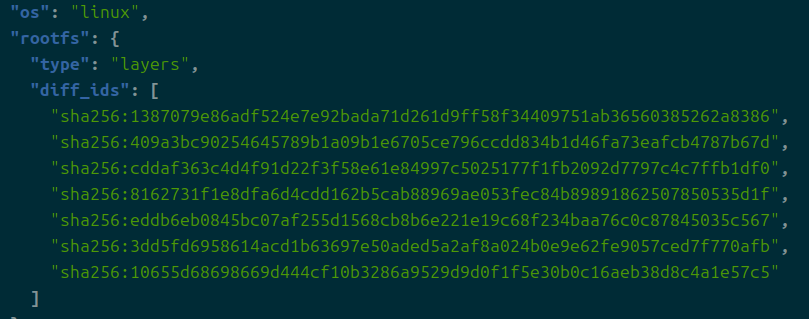
컨테이너 inspect를 할 때 레이어로 추정되는 이 녀석들은 무엇인가?
여기에 나오는 해시값은 전부 overlay2 디렉의 해시값이다.
확인해보니까 다 일일히 있더라..
그럼 도대체 이 image라는 디렉은 왜 존재하는 거야?
내 견해는 이렇다.
무거운 overlay2 디렉터리 때문이다.
근데 사용자가 docker ps 등의 명령어를 쉴 새 없이 날려댄다.
그때마다 일일히 디렉터리를 뒤져대는 건 비효율적이라 일종의 캐싱 역할로 각종 정보를 남겨두는것이다.
개인적으로는 도커가 초반에 개발된 이후로 더 효율적인 구조로 바꾸지 못한 잔재로 보이기도 한다.
뭣하러 overlay2에, 여기에 따로따로 캐싱이 존재하나.
containerd가 분리될 정도의 리팩터링을 거칠 수 있었음에도 바꾸지 않았단 것은 오히려 이럴 수밖에 없는 이유가 있었다는 것일 수도 있다.
containers
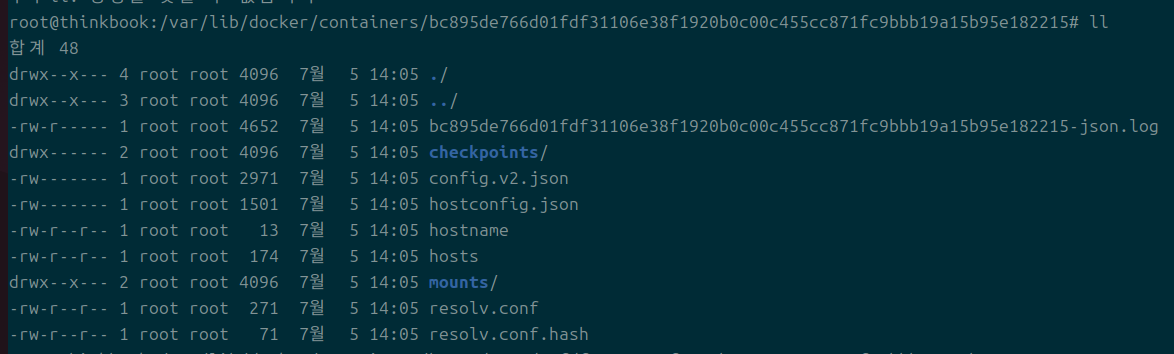
현재 추적되는 컨테이너들에 대한 정보가 담긴다.
몇 가지는 단순하게 알 수 있다.
- *json.log
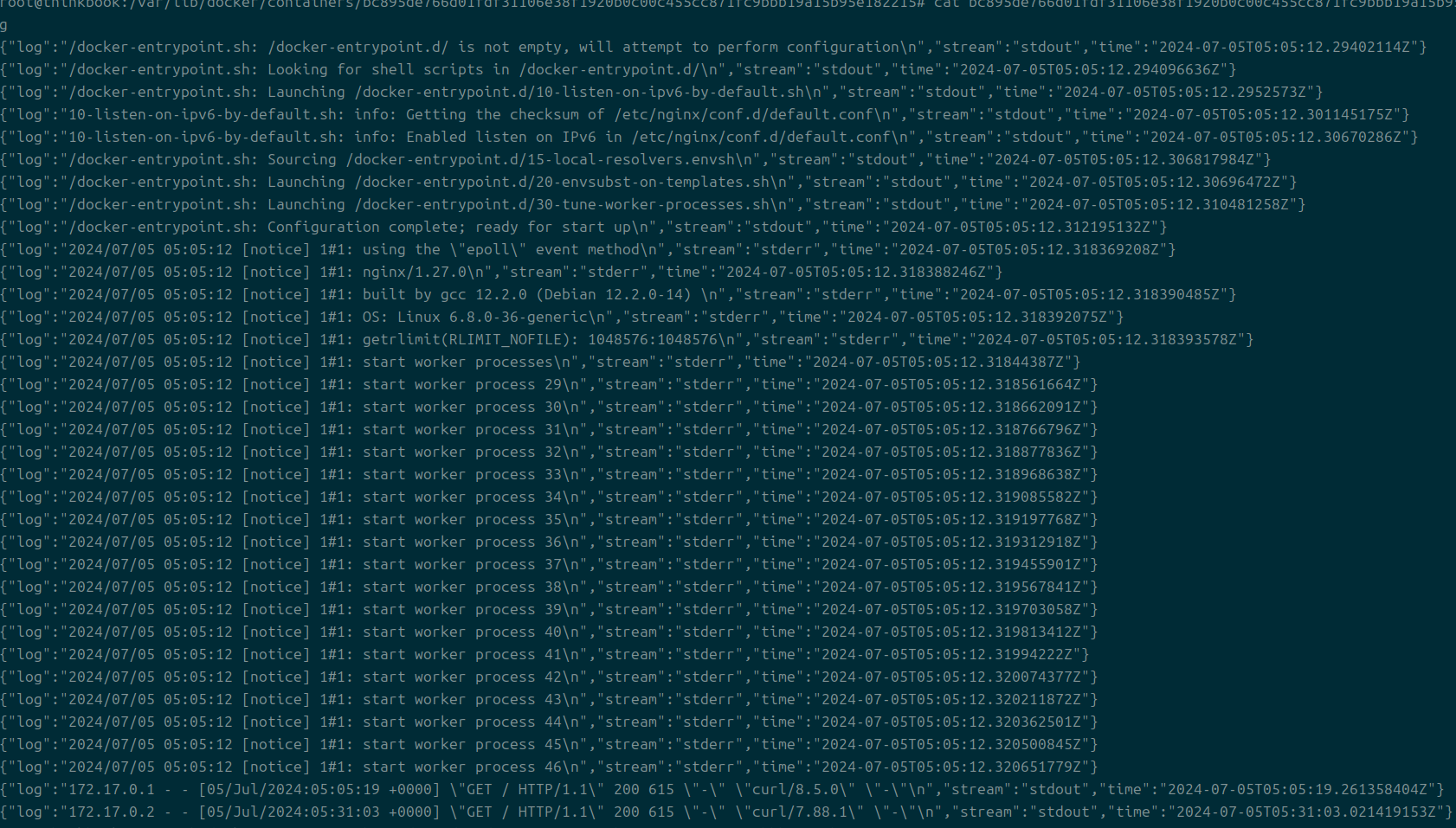
- 로그 파일을 저장하는 파일
- 이걸 통해서 우리는
docker logs를 쓸 수 있는 듯
- hostname
docker ps를 칠 때 나오는 12자리 해시값.- 내부에서도 확인할 수 있다.
- hosts
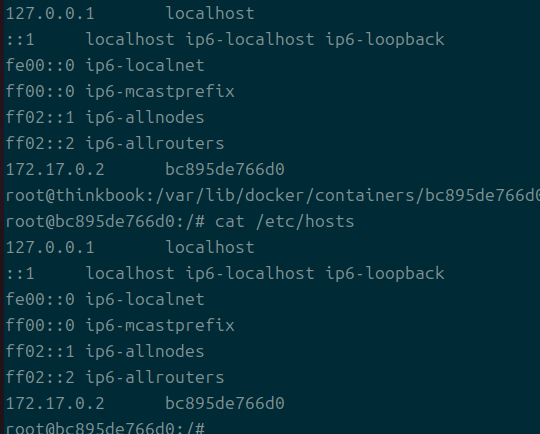
- 컨테이너 내부에 들어가게 되는 hosts 파일
- 참고로 같은 네트워크에 있는 컨테이너라도 hosts에 정보가 담기지는 않는다.
--host옵션을 사용할 때를 위해 존재하는 듯하다.- 아마 언젠가 deprecated될 거라는 것에 내 수염 한가닥을 걸겠다.
- *.json
- host, config 정보들은 컨테이너 세부 스펙을 다룬다.
- 흔히 inspect로 찾아볼 수 있는 내용들이다.
- image 디렉에 존재하는 정보 방식과 다르지 않다.
- resolve.conf
- resolve.conf는 DNS 관련 사전 설정 정보를 담는다.
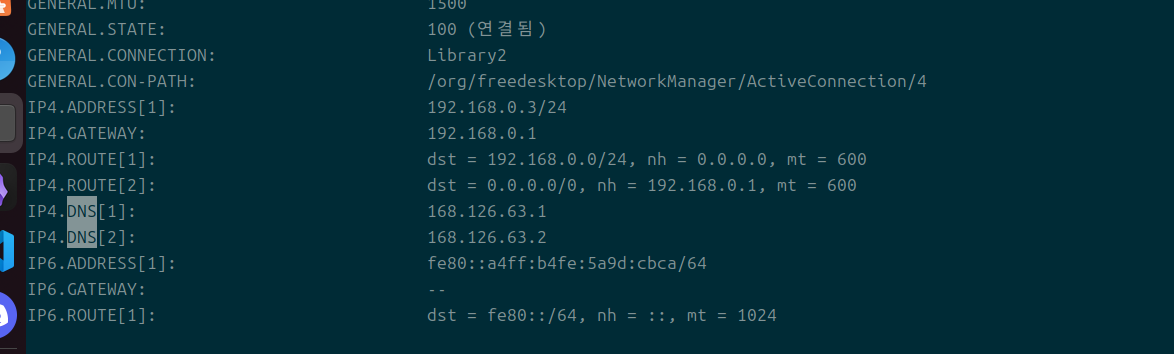
nmcli dev show를 통해 내 호스트 환경의 dns를 확인해보니 KT의 서버가 나왔다.- 컨테이너가 세워질 때도 이쪽에 대한 정보가 담기게 되며, 그렇기에 컨테이너 내부에서 문제 없이 dns를 사용할 수 있는 것이다.
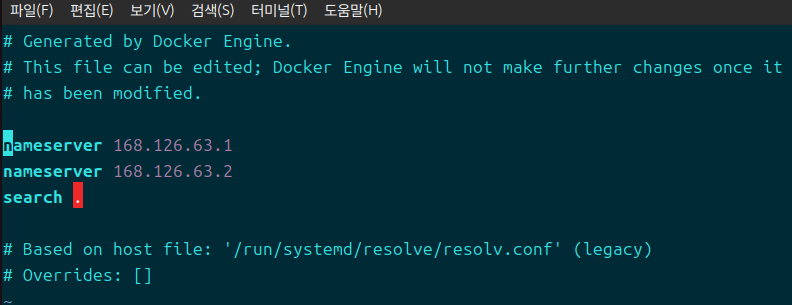
- 참고로 DNS는
resolvectl을 통해 리졸버를 탐구할 수 있다./etc/resolve.conf를 가보면 재밌는 내용들을 또 찾을 수 있는데, 127.0.0.53이 로컬 리졸버 서버로 활용된다고 한다.- DNS 탐구를 하기 위해 시작한 것은 아니니까 이건 나중에 다루도록 한다.
- checkpoints
- 도커에는 checkpoint기능이 있는데, 그것에 대한 정보가 checkpoints 디렉에 저장된다고 한다.
- mounts
- 잘 모르겠다.
- 볼륨 마운팅을 아무리 해도 아무런 일이 안 생긴다.
- volume 기능을 사용하기 이전에 혹시 기능이 있었을까?
- network가 나오고 host 옵션이 바보가 되었듯이..
해결하고 싶었던 궁금증
- 어떻게 생겨먹었지?
- 유니온 파일시스템
- 컨테이너가 생성될 때 마지막 thin layer 생성되어 자유롭게 사용 가능
- 이미지 빌드할 때 무슨 일이 발생하지?
- 도커파일에 명시된 순서에 따라 overlay2 디렉에 레이어를 저장
- 각 레이어는 l 디렉에 키값이 저장되어 빠르게 접근 가능
- 마지막 레이어가 완성되면 image 디렉에 관련된 정보를 저장
- 그걸로 컨테이너 실행할 땐 무슨 일이 발생하지?
- image 디렉에 있는 정보를 토대로 overlay2 디렉에서 참조할 파일을 확보
- 그걸 기준으로 컨테이너 초기 디렉을 overlay2에 생성
- init이 뒤에 붙은 디렉
- 초기 디렉을 통해 최종적인 컨테이너 디렉을 만들어 독립된 프로세스에 할당
- 프로세스마다 완성된 형태의 파일시스템을 가지고 있음
- 캐싱은 어디에 담기지?
- overlay2 디렉에 정보가 있기만 하다면, 그것이 곧 캐싱?
- 이게 아직 완벽하지 않다.
실습
보여주고 싶은 것
- overlay2
- image
- container
- 이미지 풀 받기
- inspect로 확인
- 실제로 내부 컨테이너 바뀌는 거 확인하기
시나리오
- 목표
- 기본적인 도커 파일 구조
- 컨테이너 층
- 레이어가 어떻게 쌓이는지
- 초기상태 보여주기
- container, image, overlay2
- 실제 데이터는 전부 overlay스토리지에 저장
- 나머지는 빠르게 정보를 보여주거나, 하는 정도의 용도에 불과
- nginx 이미지 풀
- 컨테이너 실행
- 역순으로 각 상황 보여주기
- container
- 로그랑 상황 보여주기
- 각 json 보여주기
- 얘는 왜 있냐?
- 컨테이너의 정보를 사용자가 빠르게 볼 수 있도록 미리 정리해둠
- 실행되기 직전에 정보를 저장해둠
- image
- imagedb, layerdb
- imagedb는 이미지 정보를 캐싱해놓은 값
docker images- layerdb의 값을 가리킴
- layerdb는 imagedb와 연결되어 있음
- 잠시 정리하자면, 컨테이너에서 가리킨 이미지는 여기에, 그리고 이미지가 가리키는 레이어들은 여기에
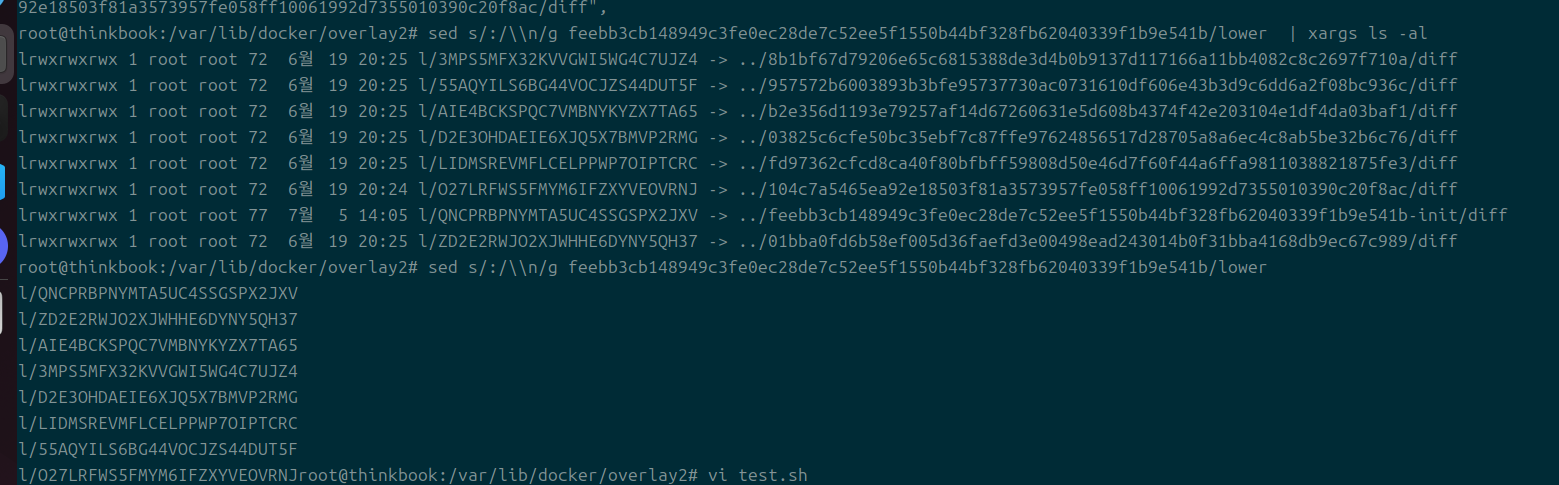
cat */diff | sed s/sha256:/\\n/g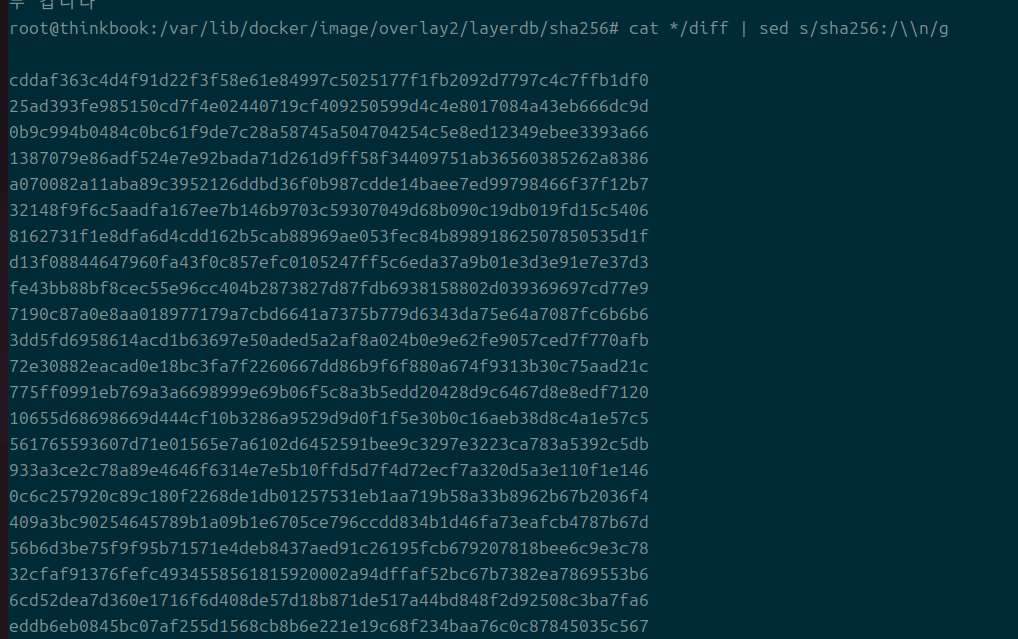
- 사실 아주 정확하게는 여기에서도 또 해싱이 들어간다.
- 해싱돼서 나온 diff가 진짜로 우리에게 표시되는 레이어 해시값이다.
- layerdb의 cache-id 하나만 따라가기
- 그냥 또 해시가 있다.
- 근데 얘는 실제로 overlay2와 연결
- 왜 다시 해싱을 했을까?
- 변형을 막기 위해?
- https://blog.naver.com/alice_k106/221149596996
- 정확히 매칭이 되는지는 모르겠으나 연관이 있어보인다.
- 결국 위변조 여지를 막기 위해서였다는 것이다.
- 생각해보자
- 실제 스토리지의 레이어들에는 각각의 해시값이 있다.
- 누가 레지스트리에 올릴 시점에 파일을 건드렸다.

- 이렇게 소용없다.
- 어차피 압축 파일로 올리니까

- 그럼 압축파일을 건드리자.
- 오류 상황을 만들어내는 것은 너무나 어려운 일이다..
- 일단 실험은 중단
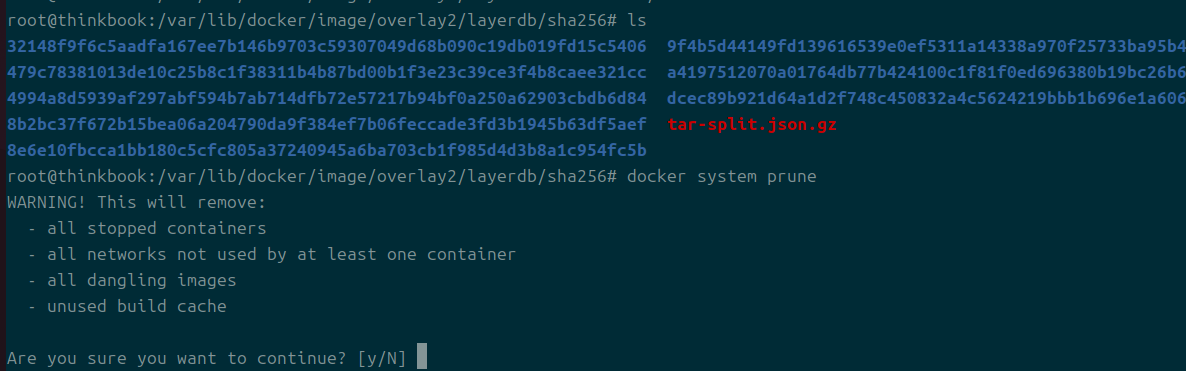
- 그 와중에.. 제대로 안 지워지는 파일도 있다는 것을 처음 알았다.
- 이걸 해결하려면
docker system prune을 해야 한다. - 하지만 레이어 해시와 다이제스트를 구분짓는다는 것만은 확실하다
- 왜 따로 레이어디비가 있을까?
- 어차피 image안에 또 파일시스템 별 디렉을 두는데
- 컨테이너 층이 따로 존재하니까.
- 이건 mounts가 따로 있어서 말이 안됨
- 아마 레지스트리랑 관련이 있겠다
- 압축 파일이 존재하는 걸 보니까 실제 레지스트리에 파일이 올라갈 때는 이러한 형태로 올라가는 게 아닐까 생각
- overlay
- 일단 l 보여주기
- 대문자 해시 또..
- 이건 이 오버레이 내부에서 쓰인다.
- 여기 디렉에 있는 값들은 아까 이미지디비에 있던 값들
- 그리고 컨테이너와 관련한 값
- 컨테이너는 레이어 한층
- 실제 만들어지는 동작은 두 번이라고 보면 댐
- 먼저 init이라는 이름으로 하나 만들고, 그거에 최종을 만든다.
- init은 컨테이너 생성 시점에 초기화를 진행하는 정보가 담기는 디렉터리
- 보면 아까 컨테이너 디렉에서 봤던 값 담긴다.
- 추가적으로 각종 시그널을 받을 수 있는 처리한다고 함
- 이후에 init을 뗀 디렉터리에 실행시점에 생기는 변화들이 담긴다.
- 이게 진짜 사용자가 마주하는 디렉
- 일단 l 보여주기